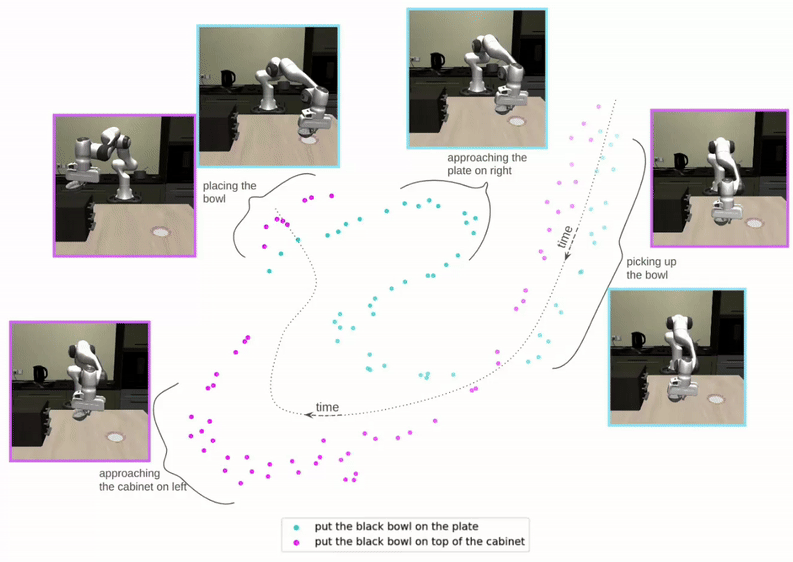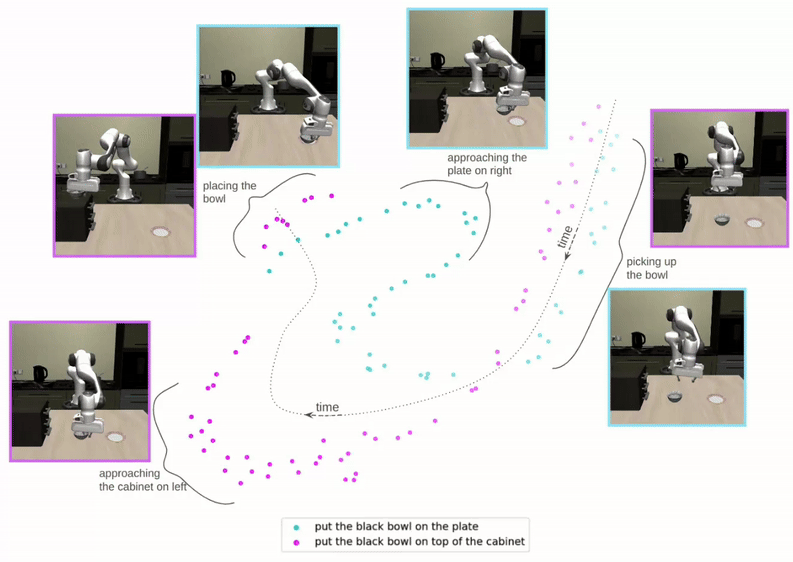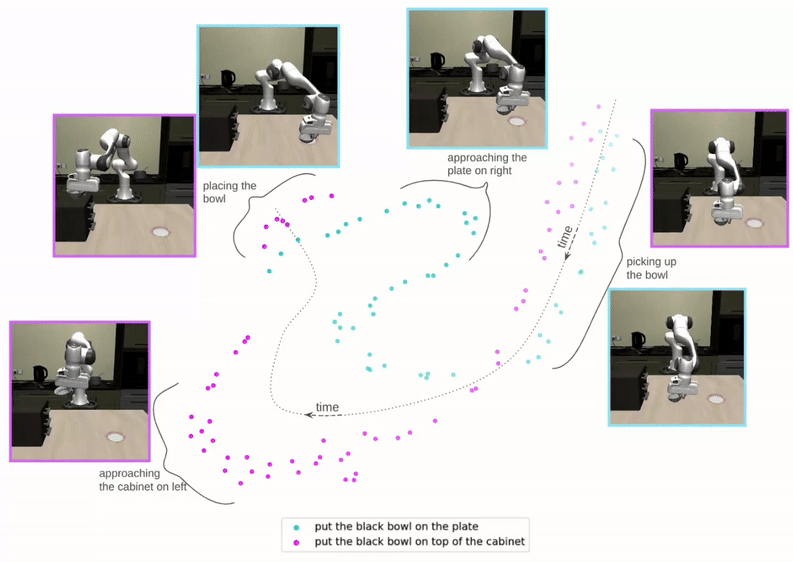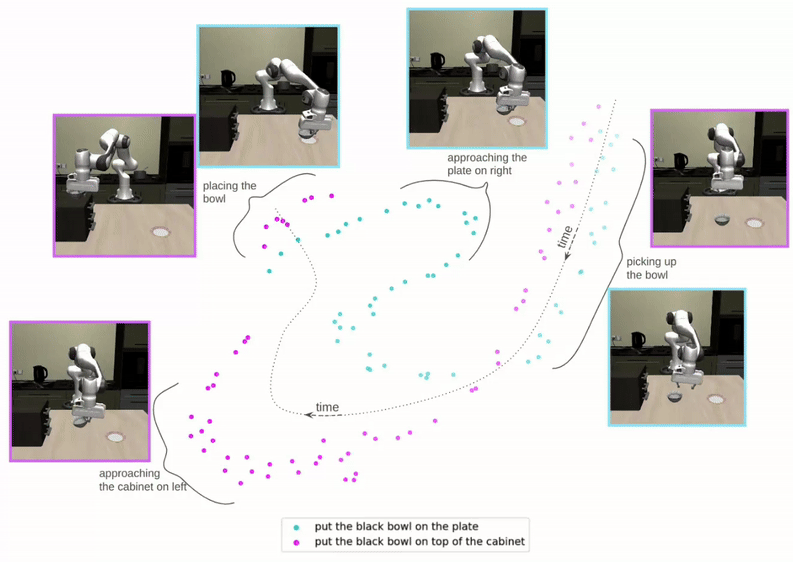
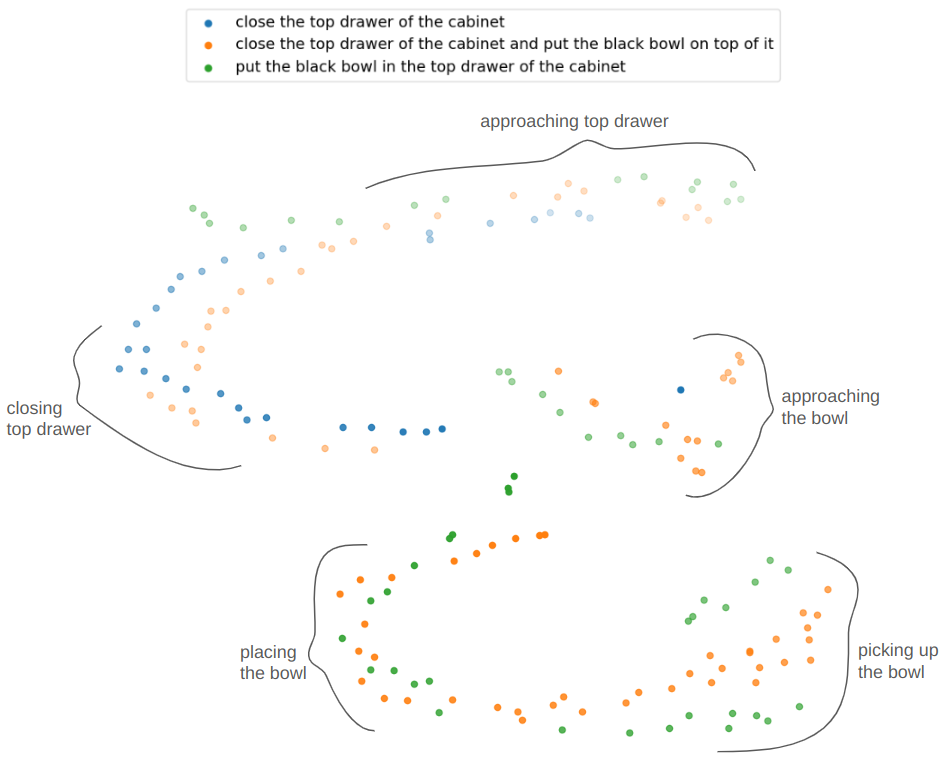
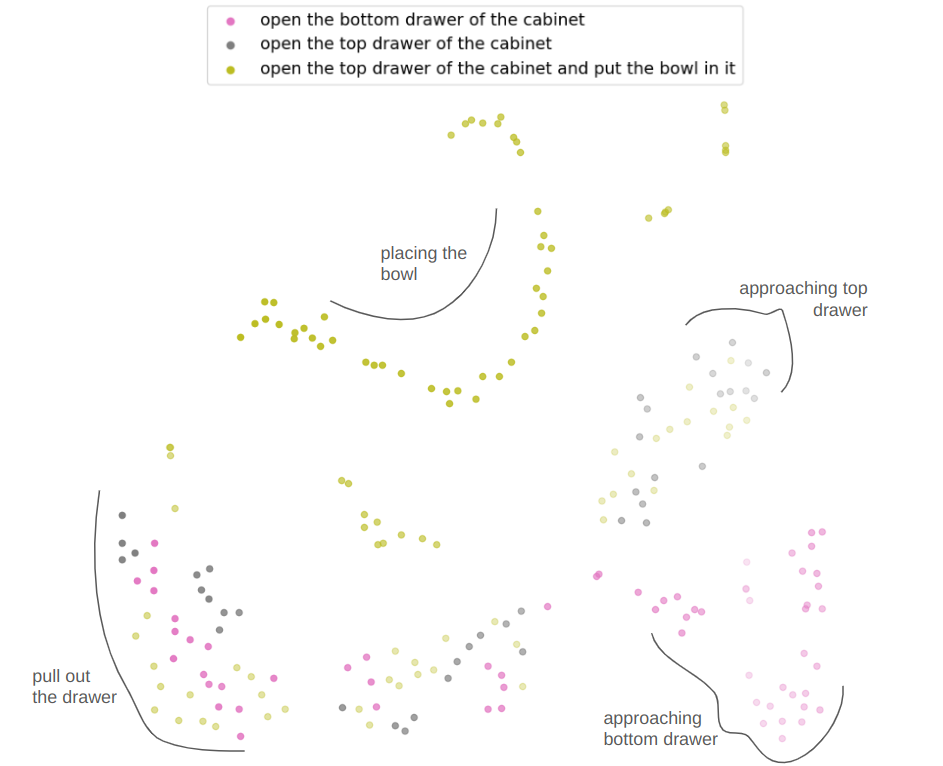
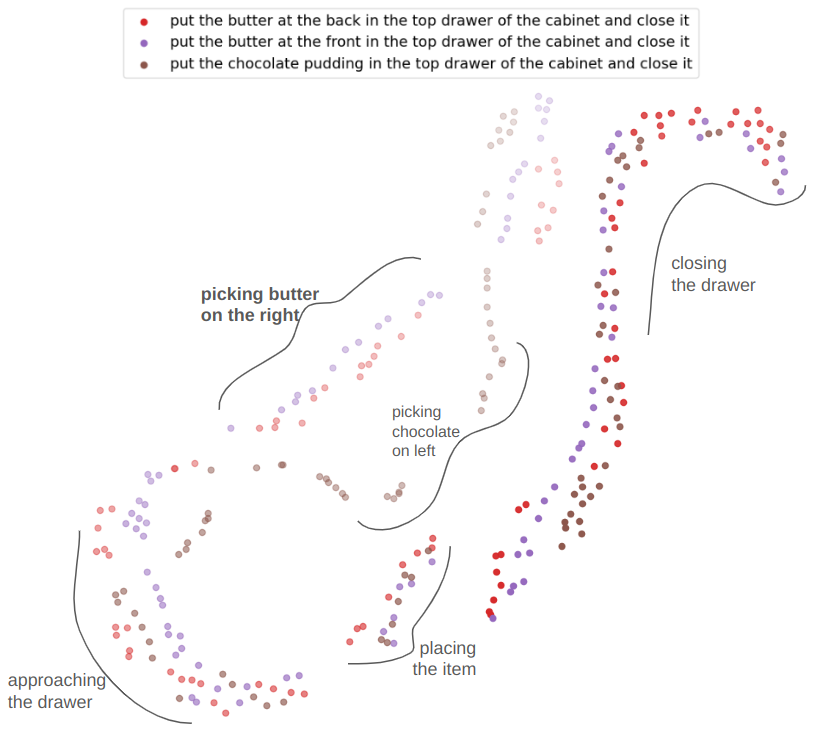
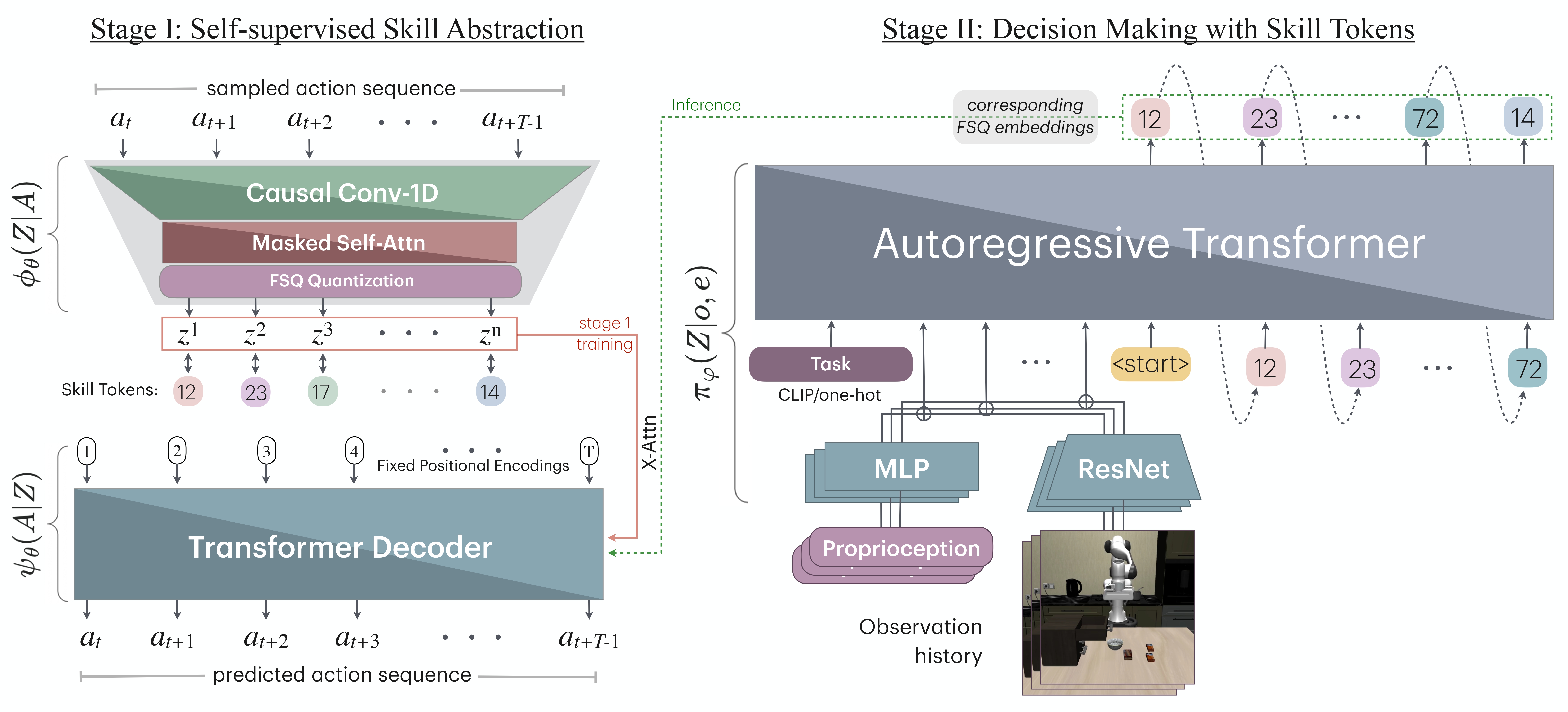
Proposed Architecture
We factorize QueST into two stages. Stage-I maps a sequence of continuous actions to a sequence of discrete skill tokens. Stage-II learns a skill-based policy in the style of next-token prediction using a multi-modal GPT-like transformer.
Simulated Benchmarks
Multitask Learning
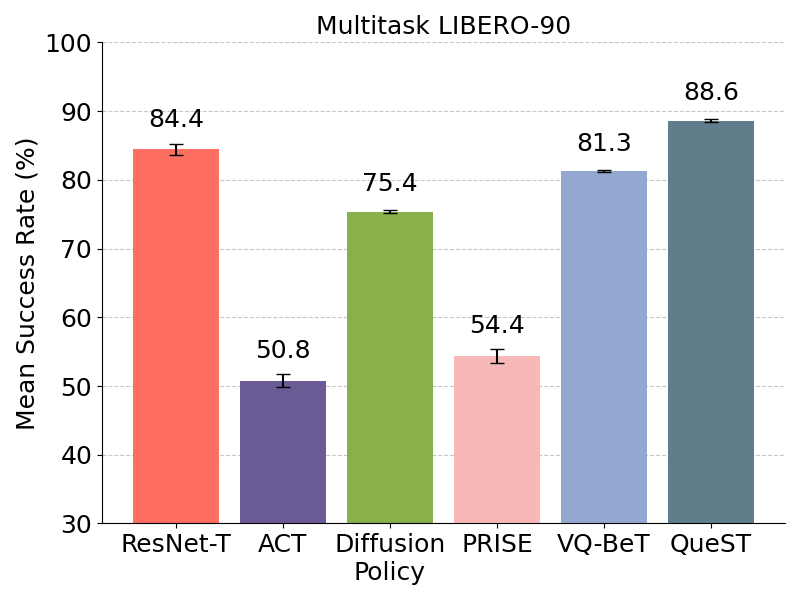
Relative improvement of at least 10.3% over VQ-BeT and Diffusion Policy on LIBERO-90 benchmark with 90 tasks.
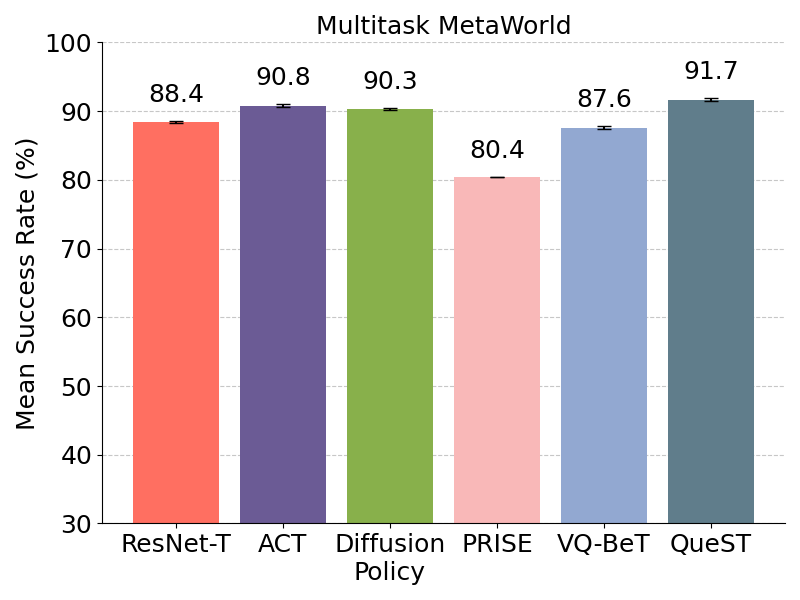
MetaWorld being a simpler benchmark, all methods perform almost similar across 45 tasks.
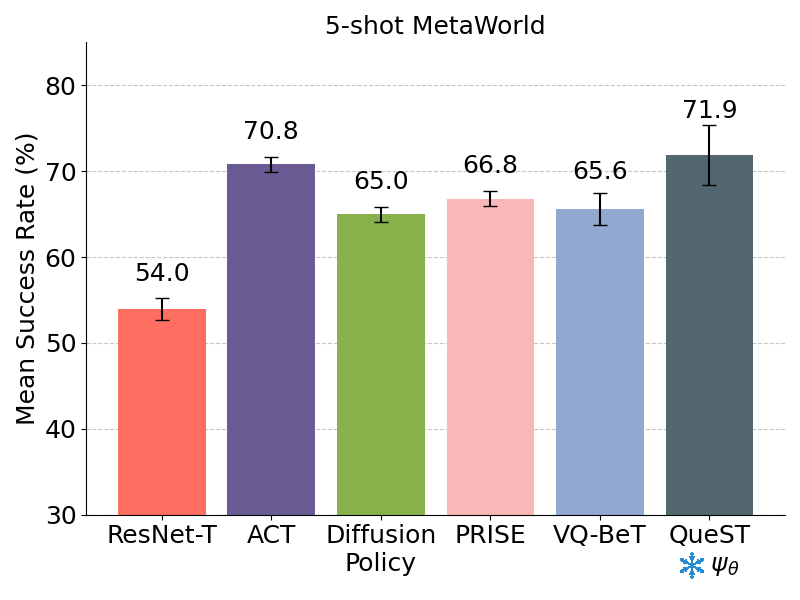
5-Shot Adaptation
 - denotes decoder frozen in finetuning
- denotes decoder frozen in finetuning
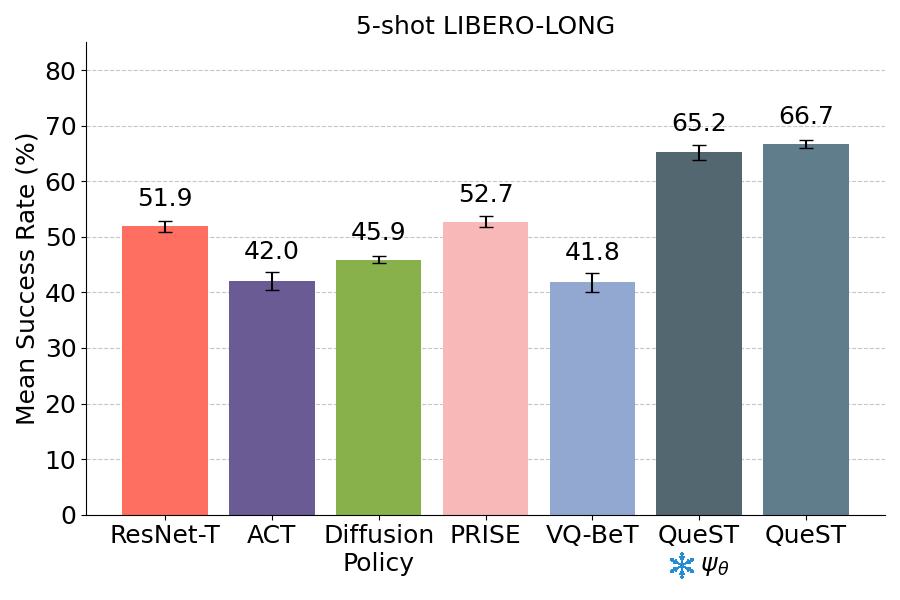
Relative improvement of 24% over next best baseline on 10 unseen tasks from LIBERO-LONG benchmark
All methods perform comparably, with QueST showing a slight improvement over the others across 5 held-out tasks in MetaWorld